Optimizers¶
What is Optimizer ?
It is very important to tweak the weights of the model during the training process, to make our predictions as correct and optimized as possible. But how exactly do you do that? How do you change the parameters of your model, by how much, and when?
Best answer to all above question is optimizers. They tie together the loss function and model parameters by updating the model in response to the output of the loss function. In simpler terms, optimizers shape and mold your model into its most accurate possible form by futzing with the weights. The loss function is the guide to the terrain, telling the optimizer when it’s moving in the right or wrong direction.
Below are list of example optimizers
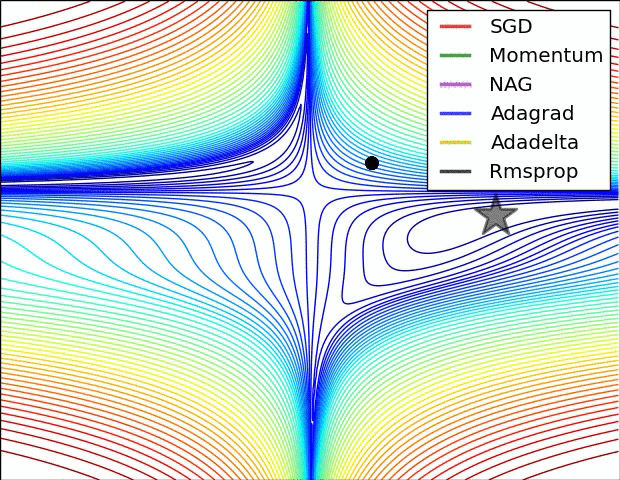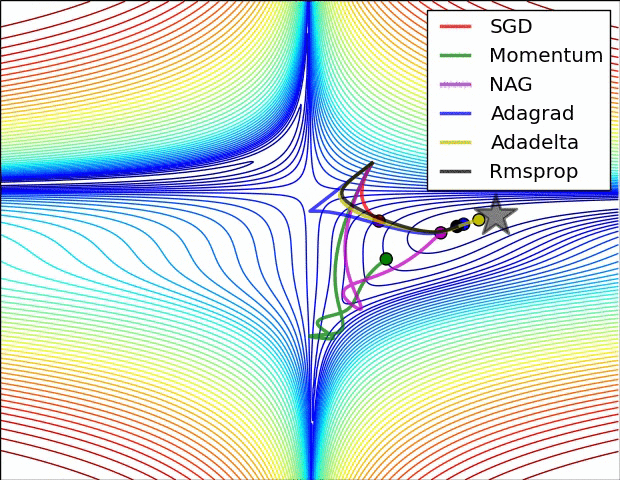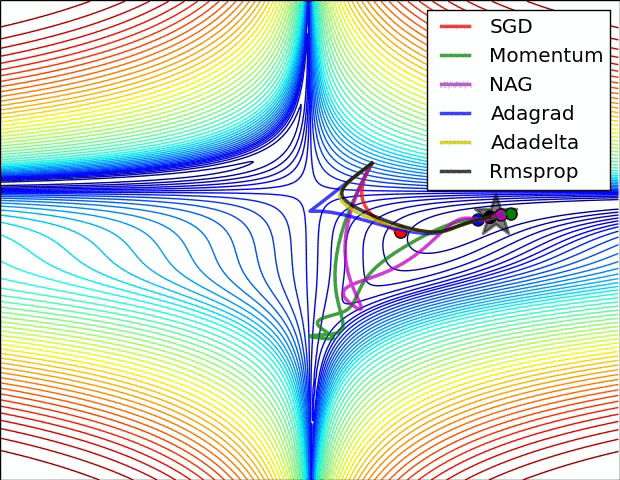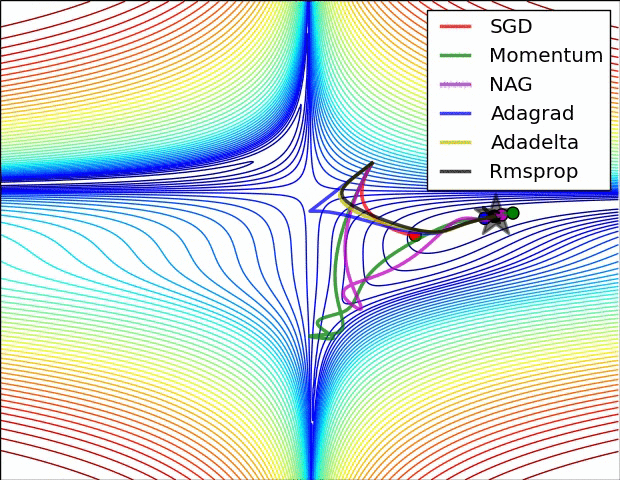
Image Credit: CS231n
Adagrad¶
Adagrad (short for adaptive gradient) adaptively sets the learning rate according to a parameter.
- Parameters that have higher gradients or frequent updates should have slower learning rate so that we do not overshoot the minimum value.
- Parameters that have low gradients or infrequent updates should faster learning rate so that they get trained quickly.
- It divides the learning rate by the sum of squares of all previous gradients of the parameter.
- When the sum of the squared past gradients has a high value, it basically divides the learning rate by a high value, so the learning rate will become less.
- Similarly, if the sum of the squared past gradients has a low value, it divides the learning rate by a lower value, so the learning rate value will become high.
- This implies that the learning rate is inversely proportional to the sum of the squares of all the previous gradients of the parameter.
Note
- \(g_{t}^{i}\) - the gradient of a parameter, :math: `Theta ` at an iteration t.
- \(\alpha\) - the learning rate
- \(\epsilon\) - very small value to avoid dividing by zero
Adadelta¶
AdaDelta belongs to the family of stochastic gradient descent algorithms, that provide adaptive techniques for hyperparameter tuning. Adadelta is probably short for ‘adaptive delta’, where delta here refers to the difference between the current weight and the newly updated weight.
The main disadvantage in Adagrad is its accumulation of the squared gradients. During the training process, the accumulated sum keeps growing. From the above formala we can see that, As the accumulated sum increases learning rate to shrink and eventually become infinitesimally small, at which point the algorithm is no longer able to acquire additional knowledge.
Adadelta is a more robust extension of Adagrad that adapts learning rates based on a moving window of gradient updates, instead of accumulating all past gradients. This way, Adadelta continues learning even when many updates have been done.
With Adadelta, we do not even need to set a default learning rate, as it has been eliminated from the update rule.
Implementation is something like this,
Adam¶
Adaptive Moment Estimation (Adam) combines ideas from both RMSProp and Momentum. It computes adaptive learning rates for each parameter and works as follows.
- First, it computes the exponentially weighted average of past gradients (\(v_{dW}\)).
- Second, it computes the exponentially weighted average of the squares of past gradients (\(s_{dW}\)).
- Third, these averages have a bias towards zero and to counteract this a bias correction is applied (\(v_{dW}^{corrected}\), \(s_{dW}^{corrected}\)).
- Lastly, the parameters are updated using the information from the calculated averages.
Note
- \(v_{dW}\) - the exponentially weighted average of past gradients
- \(s_{dW}\) - the exponentially weighted average of past squares of gradients
- \(\beta_1\) - hyperparameter to be tuned
- \(\beta_2\) - hyperparameter to be tuned
- \(\frac{\partial \mathcal{J} }{ \partial W }\) - cost gradient with respect to current layer
- \(W\) - the weight matrix (parameter to be updated)
- \(\alpha\) - the learning rate
- \(\epsilon\) - very small value to avoid dividing by zero
Conjugate Gradients¶
Be the first to contribute!
BFGS¶
Be the first to contribute!
Momentum¶
Used in conjunction Stochastic Gradient Descent (sgd) or Mini-Batch Gradient Descent, Momentum takes into account past gradients to smooth out the update. This is seen in variable \(v\) which is an exponentially weighted average of the gradient on previous steps. This results in minimizing oscillations and faster convergence.
Note
- \(v\) - the exponentially weighted average of past gradients
- \(\frac{\partial \mathcal{J} }{ \partial W }\) - cost gradient with respect to current layer weight tensor
- \(W\) - weight tensor
- \(\beta\) - hyperparameter to be tuned
- \(\alpha\) - the learning rate
Nesterov Momentum¶
Be the first to contribute!
Newton’s Method¶
Be the first to contribute!
RMSProp¶
Another adaptive learning rate optimization algorithm, Root Mean Square Prop (RMSProp) works by keeping an exponentially weighted average of the squares of past gradients. RMSProp then divides the learning rate by this average to speed up convergence.
Note
- \(s\) - the exponentially weighted average of past squares of gradients
- \(\frac{\partial \mathcal{J} }{\partial W }\) - cost gradient with respect to current layer weight tensor
- \(W\) - weight tensor
- \(\beta\) - hyperparameter to be tuned
- \(\alpha\) - the learning rate
- \(\epsilon\) - very small value to avoid dividing by zero
SGD¶
SGD stands for Stochastic Gradient Descent.In Stochastic Gradient Descent, a few samples are selected randomly instead of the whole data set for each iteration. In Gradient Descent, there is a term called “batch” which denotes the total number of samples from a dataset that is used for calculating the gradient for each iteration. In typical Gradient Descent optimization, like Batch Gradient Descent, the batch is taken to be the whole dataset. Although, using the whole dataset is really useful for getting to the minima in a less noisy or less random manner, but the problem arises when our datasets get really huge.
This problem is solved by Stochastic Gradient Descent. In SGD, it uses only a single sample to perform each iteration. The sample is randomly shuffled and selected for performing the iteration.
Since only one sample from the dataset is chosen at random for each iteration, the path taken by the algorithm to reach the minima is usually noisier than your typical Gradient Descent algorithm. But that doesn’t matter all that much because the path taken by the algorithm does not matter, as long as we reach the minima and with significantly shorter training time.
References
| [1] | https://ruder.io/optimizing-gradient-descent/ |
| [2] | http://www.deeplearningbook.org/contents/optimization.html |
| [3] | https://arxiv.org/pdf/1502.03167.pdf |